背景
系统突然重启,需要排查原因,就想到dmesg和/var/log/message,打开dmesg没发现时间,没时间这可怎么查问题?
解决方案
遇到这类问题首先想到的就是G一下,网上肯定有人问这种问题,你所遇到的问题肯定是别人之前已经遇到过的,所以,放马去搜索吧。所有问题都这样,原来dmesg里面第一列的浮点数是跟uptime有一定的关系,利用date命令可以转换,这里写了个脚本记录一下
|
|
很简单,几行代码就搞定!
系统突然重启,需要排查原因,就想到dmesg和/var/log/message,打开dmesg没发现时间,没时间这可怎么查问题?
遇到这类问题首先想到的就是G一下,网上肯定有人问这种问题,你所遇到的问题肯定是别人之前已经遇到过的,所以,放马去搜索吧。所有问题都这样,原来dmesg里面第一列的浮点数是跟uptime有一定的关系,利用date命令可以转换,这里写了个脚本记录一下
|
|
很简单,几行代码就搞定!
最近在升级php7, php7的opcache的一个选项opcache.revalidate_freq的默认值是60,之前线上php5.5.6中opcache的opcache.revalidate_freq设置的为2。然后在上线代码的时候总是会出现php的error, 这种情况被称为”瞬报”。 当上线的文件较多的时候,这种错误可能会持续很长时间,但是op也不太care, 总觉得无所谓,所以一直也没处理,只需要在上线的时候在群里通报一声:”我在上线,有php-error的话属于瞬报,无视即可”。好尴尬,哈哈。
上线的时候,收到php-error后,通常都很紧张,这尼玛难道有问题,要回滚啊!!!赶紧看看php-error是什么造成的。打开一看尼玛A文件的a方法调用B文件中的b方法是出错,说B文件中不存在b这个方法,怎么可能我tmd这次上线新加的b方法啊,连水都没顾得上喝,赶紧去打开B文件看,果然B文件里面有b方法。
出现这种问题的原因是什么呢?罪魁祸首是什么呢?当然最根本的原因就是上线是非原子的。所谓上线代码的原子性即你上线的文件要同时生效不能存在你上线的A文件调用的是上线之前版本的B文件,这样导致最终的结果是跟预期相悖的,也是不可预测的。
那么导致这个问题出现的原因有几种呢?
说到opcache,目前最常用的有后面几种apc、 eaccelerator、 ZendOpcache,apc 的 bug 很多,比如开启了apc.enable_cli 配置后就会有很多灵异问题。随着ZendOpcache被内置到官方的PHP版本中,ZendOpcache使用也越来越广泛,当然效果也是非常好的。所以还是使用ZendOpcache吧。此外apc和ZendOpcache对文件的缓存键也不同,apc按照文件的inode,Zendopcache选择了文件的path。
接上面,如果A的opcache先过期,B的后过期,就可能导致上面说的那种非”原子发布”导致不可预知的问题。
这里说的不是普通的文件缓存,说的是realpath缓存,php在include或者requrire文件的时候并不是每次都去通过stat系统调用判断文件是否存在,如果存在就加载进内存,加载过之后php对文件会进行一个优化,PHP会根据文件的path去缓存该文件的stats信息,通过如下代码可以验证
|
|
输出结果:
|
|
你可以使用clearstatcache(true)清空这个array,强制PHP去通过stat()系统调用获取文件的信息,尽管之前已经被访问过。另外realpath是进程级别的,非共享内存级别。更多reaplpath cache相关的东西可以参考 http://jpauli.github.io/2014/06/30/realpath-cache.html。
这块主要是影响那些通过修改软链接形式的上线系统,因为realpath cache的存在可能导致代码不生效。
以上两种问题都需要考虑如何解决,如果是通过修改软链接的形式上线的,需要同时处理realpath cache、opcache的缓存,否则只需要处理opcache缓存即可。
当然方案都是两种一种是自动过期、一种是手动过期。
自动过期
可以通过修改php.ini里 realpath_cache_size、realpath_cache_ttl实现。
当然如果你使用的nginx + php-fpm的形式,你可以通过修改nginx的fastcgi_params实现,配置如下:
|
|
这样当你修改网站目录的软链时,nginx会自己判断你网站根目录的真实路径,当然代价还是stat的系统调用,只不过把php的stat转移到了nginx。
软链的方法推荐使用ln -sfn处理。
手动过期
可以通过调用clearstatcache(true)去清除
自动过期
如果你使用的是ZendOpcache 你可以设置opcache.validate_timestamps=1,opcache.revalidate_freq=0 当然代价是每次请求都回去检查文件的最后修改时间,无谓增加一堆stat系统调用,性能可想而知。
手动过期
可以通过设置opcache.validate_timestamps=0去关闭ZendOpcache的自动检测文件是否更新操作,上线完毕后手工调用opcache_reset()或者opcache_invalidate(string $script [, boolean $force = FALSE ] ),需要注意的是opcache_reset是重置所有的opcache,或者opcache_invalidate可以针对单个文件。当然最粗暴的方法就是重启fpm进行(Kill SIGUSR2强制也可以),性能会有些许损失,还是建议通过清楚opcache的方式去处理。
BTW:如果需要手动重置 opcode cache,需要注意的是因为它是基于 SAPI 的概念,所以不能直接在命令行下调用 apc_clear_cache 或者 opcache_reset 方法来重置缓存,当然办法总是有的,那就是使用 CacheTool 在命令行下模拟 fastcgi 请求。
把opcache、realpath尽可能的设置的时间长一些或者永不自动过期,通过手动清除的方式清楚去清除。
很多人都在使用ZendOpcache了,但是很多人都不知道怎么去设置。
你是否注意到你是如何在没有范例或者一个真实线上存在的实例供学习花费的情况下花几个小时去读文档,但是还是不知道如何去设置这些选项?
比如,你懂得opcache.memory_consumption意味着什么,但是谁知道它应该设置多少?32是不是太大了或许太小了?Google半天什么都发现,只能根据自己的直觉去设置,谁设置过谁知道。
但是,如果你的直接是错误的呢?你愿意通过你的猜测去赌一把吗?
我不是这样的。
在研究方面我有一个很可怕的像狂人一样的坏习惯,我会用Google搜索一些奇怪的设置并且我会花三个小时去从PHP的源码中进行挖掘。
与其让这些知识浪费,我更想与你分享。我不得不花时间搞清楚了Zend Opcache的真实生产环境的最佳设置。
这些设置是从我众多APP中的一个每天访问量1.17亿HTTP请求的APP的php.ini中直接拿出来的。我将解释每一个选项是干嘛的还有为什么这么设置,你可以根据你自己的情况进行调整。
opcache.revalidate_freq - 简单的说,多久(单位是秒)检查一次你的代码缓存(opcache)是否过期。0代表每一个请求都回去检查你的PHP代码(代价比较大,每次请求会添加很多stat的系统调用去检查文件的最后修改时间,而每次每次系统调用都涉及到内核的中断还有上下文的切换,代价比较大)。在开发环境可以直接设置为0,生产环境下设置跟下一个设置项有关。
opcache.validate_timestamps - 当这个选项开启的时候,PHP将每隔(你设置的opcache.revalidate_freq 的值)秒去检查文件的最后修改时间。
当你未开启该选项的时候,opcache.revaliate_freq的设置会被忽略,你的PHP文件将永远不会因为代码更新去检查文件修改时间。因此,如果你修改了你的代码,修改将不会生效直到你重启PHP(或者强制通过Kill -SIGUSR2)。
是的,这感觉有点痛苦并且荒唐,但是你应该去使用它,为什么呢?当你更新或者部署代码的时候新代码可能会与旧代码掺杂在一起,那运行结果就不可知了,像地狱一样不安全。
opcache.max_accelerated_files - 控制一次最多可以加载多少个PHP文件到内存。将这个值设置的比你工程的PHP文件多是非常重要的。我的代码库有不到6000个文件,所以我选择了一个比6000大的质数7963作为最大加速文件的个数。
你可以通过find . -type f -print | grep php | wc -l快速计算出你代码仓库里有多少个文件。
opcache.memory_consumption - 默认值是64M,因为我有一吨代码,所以我把这个值设置为192M。你可以使用opcache_get_status()方法查看opcache目前消耗的内存(下周可能会更多)进而判断你是否需要增加这个设置的值。
opcache.interned_strings_buffer - 关于这个选项的文档数基本是0,PHP使用了一个叫做内部字符串技术来提升性能,比如在你代码里面使用了1000次foobar字符串,PHP内部只存储foobar这个字符串一次不可变字符串,另外的999次使用指针去指向内部字符串,更深层次的说,这个设置并不是为每个php-fpm进程设置一个不可变的字符串的池,而是所有的php-fpm进程共享的,它节省内存,提高性能,在大的应用中效果更显著。
它的值单位是M,所以”16”代表16MB,默认值比较小4MB。
opcache.fast_shutdown - 另外一个有趣的但没有用文档的选项,”允许快速关闭”,哦,好的,就像解释的这样,它实际上做的是提供一个快速调用你代码中析构函数的机制加速一个单个请求的相应,加速php worker的回收进行更快的准备处理下一个请求。设置为1代表打开它。
另外在缺省情况下 opcache.revalidate_path 是关闭的,此时会缓存符号链接的值,这会导致即便软链接指向修改了,也永远无法生效,所以在使用 zend opcode 的时候,如果使用了软链接,视情况可能需要把 opcache.revalidate_path 激活。
php.ini中设置如下
|
|
原文: https://www.scalingphpbook.com/blog/2014/02/14/best-zend-opcache-settings.html
OpenResty群里抛出一个如下的问题
===========技术点,征解决代码
如何把网络传输的 float 数字转换成 lua 可以识别的 number ?
float 类型,在网络字节流中是0x00 0x00 0xFB 0x42,它所对应的实际值是 125.5 。请问如果在 lua 中获取到字节流后,如何把他转成我们需要的 125.5 ?
同样的,double 类型也需要类似代码。
这玩意看着挺简单,想着通过ffi,搞个atof不就可以了吗?自己试了下发现,结果不对,一直是0。过了一会一位同学直接抛出了代码,最后说了句 “union做类型转换,最好用了。。”, 由于咱C语言学的不太好,根本没听过这方法啊,于是Google了一番,也算是记个笔记。
|
|
|
|
该方法确实挺好用,atof不能处理这种数据,另外补充一下lua的string如何转换成c_str
|
|
反之通过ffi.string即可
LRU是Least Recently Used的缩写,意思是最近最少使用,它是一种Cache替换算法。 什么是Cache?狭义的Cache指的是位于CPU和主存间的快速RAM, 通常它不像系统主存那样使用DRAM技术,而使用昂贵但较快速的SRAM技术。 广义上的Cache指的是位于速度相差较大的两种硬件之间, 用于协调两者数据传输速度差异的结构。除了CPU与主存之间有Cache, 内存与硬盘之间也有Cache,乃至在硬盘与网络之间也有某种意义上的Cache── 称为Internet临时文件夹或网络内容缓存等。
Cache的容量有限,因此当Cache的容量用完后,而又有新的内容需要添加进来时, 就需要挑选并舍弃原有的部分内容,从而腾出空间来放新内容。LRU Cache 的替换原则就是将最近最少使用的内容替换掉(还有一种是FIFO方式进行缓存替换)。其实,LRU译成最久未使用会更形象, 因为该算法每次替换掉的就是一段时间内最久没有使用过的内容。
LRU一般是由双向链表结合一个hash结构实现, 双向链表用于存储数据结点,并且它是按照结点最近被使用的时间来存储的。 如果一个结点被访问了, 我们有理由相信它在接下来的一段时间被访问的概率要大于其它结点。于是, 我们把它放到双向链表的头部。当我们往双向链表里插入一个结点, 我们也有可能很快就会使用到它,同样把它插入到头部。 我们使用这种方式不断地调整着双向链表,链表尾部的结点自然也就是最近一段时间, 最久没有使用到的结点。那么,当我们的Cache满了, 需要替换掉的就是双向链表中最后的那个结点(不是尾结点,头尾结点不存储实际内容)。
LRUCache对外暴露三个接口
Get(K key)
Put(K key, V value)
当我们初始化的时候只需要调用NewLRUCache(capacity)即可初始化我们的Cache的容量,需要塞数据的时候调用Put方法,需要获取数据的时候调用Get方法。
当我们通过键值来访问类型为T的数据时,调用Get函数。如果键值为key的数据不存在在Cache中就返回-1;如果已经在 Cache中,那就返回该数据,同时将存储该数据的结点移到双向链表头部。 如果我们查询的数据不在Cache中,我们就可以通过Put接口将数据插入双向链表中。 如果此时的Cache还没满,那么我们将新结点插入到链表头部, 同时用哈希表保存结点的键值及结点地址对。如果Cache已经满了, 我们就将链表中的最后一个结点(注意不是尾结点)的内容替换为新内容, 然后移动到头部,更新哈希表。
➜ lru cat lru.go
package lru
import "fmt"
type Node struct {
Key interface{}
Value interface{}
Prev *Node
Next *Node
}
type LRUCache struct {
Head, Tail *Node
Capacity int
Map map[interface{}]*Node
}
func NewLRUCache(capacity int) *LRUCache {
l := &LRUCache{}
l.Capacity = capacity
l.Head = &Node{}
l.Tail = &Node{}
l.Head.Next = l.Tail
l.Tail.Prev = l.Head
l.Head.Prev = nil
l.Tail.Next = nil
l.Map = make(map[interface{}]*Node)
return l
}
//分离节点
func (l *LRUCache) detach(n *Node) {
n.Prev.Next = n.Next
n.Next.Prev = n.Prev
}
//节点插入头部
func (l *LRUCache) attach(n *Node) {
n.Prev = l.Head
n.Next = l.Head.Next
l.Head.Next = n
n.Next.Prev = n
}
func (l *LRUCache) Put(k interface{}, v interface{}) {
oldV, ok := l.Map[k]
if ok {
l.detach(oldV)
oldV.Value = v
} else {
var n *Node
if len(l.Map) >= l.Capacity {
n = l.Tail.Prev
l.detach(n)
delete(l.Map, n.Key)
} else {
n = new(Node)
}
n.Key = k
n.Value = v
l.Map[k] = n
l.attach(n)
}
}
func (l *LRUCache) Get(k interface{}) interface{} {
v, ok := l.Map[k]
if ok {
l.detach(v)
l.attach(v)
return v.Value
}
return -1
}
func main() {
l := NewLRUCache(10)
l.Put("str", 1)
fmt.Println(l.Get("str"))
l.Put(1, 2)
fmt.Println(l.Get(1))
fmt.Println(l.Get("str").(int))
}
➜ lru cat lru_test.go
package lru
import (
"testing"
)
func testEq(a, b []int) bool {
if a == nil && b == nil {
return true
}
if a == nil || b == nil {
return false
}
if len(a) != len(b) {
return false
}
for i := range a {
if a[i] != b[i] {
return false
}
}
return true
}
func Test_Get(t *testing.T) {
l := NewLRUCache(2)
l.Put("sky", "SKY")
if l.Get("sky") != "SKY" {
t.Error("test get sky failed!!!")
} else {
t.Log("test get sky success")
}
l.Put("sky1", 2)
if l.Get("sky1") != 2 {
t.Error("test get sky1 failed!!!")
} else {
t.Log("test get sky1 success")
}
l.Put("sky2", []int{1, 2})
if testEq(l.Get("sky2").([]int), []int{1, 2}) {
t.Log("test get sky2 success")
} else {
t.Error("test get sky2 failed!!!")
}
if l.Get("sky") != -1 {
t.Error("test get sky failed!!!")
} else {
t.Log("test get sky success")
}
if l.Get("sky1") != 2 {
t.Error("test get sky1 failed!!!")
} else {
t.Log("test get sky1 success")
}
}
func BenchmarkAdd(b *testing.B) {
l := NewLRUCache(100)
for i := 0; i < b.N; i++ {
l.Put(i, i*i)
}
}
➜ lru go version
go version go1.5 linux/amd64
➜ lru go test -v lru.go lru_test.go
=== RUN Test_Get
--- PASS: Test_Get (0.00s)
lru_test.go:31: test get sky success
lru_test.go:37: test get sky1 success
lru_test.go:41: test get sky2 success
lru_test.go:48: test get sky success
lru_test.go:54: test get sky1 success
PASS
ok command-line-arguments 0.003s
➜ lru go test -test.bench=".*" lru_test.go lru.go
PASS
BenchmarkAdd-2 3000000 421 ns/op
ok command-line-arguments 1.695s
lua_package_path “conf/lua/?.lua”; 表示多个字符串的通配符为?,不是 *
lua中涉及到路径,如果没有指定绝对路径,那前缀为 安装 openresty 的 路径前缀。比如
|
|
debug
|
|
修改完代码后,不用reload nginx就可以生效了。在生产环境下记得打开这个选项。
读取post数据:curl -XPOST ‘xxxxx/test’ -d ‘a=xxx&b=yyy’
|
|
local file = ngx.req.get_body_file() 获取文件内容
|
|
ngx.location.capture
|
|
res包括:
res.status, res.header, res.body, and res.truncated
The args option can specify extra URI arguments, for instance,
|
|
is equivalent to
|
|
that is, this method will escape argument keys and values according to URI rules and concatenate them together into a complete query string. The format for the Lua table passed as the args argument is identical to the format used in thengx.encode_args method.
The args option can also take plain query strings:
|
|
ngx.location.capture_multi :同时捕获多个链接输出
The ngx.location.capture and ngx.location.capture_multi directives cannot capture locations that include the add_before_body, add_after_body, auth_request, echo_location, echo_location_async, echo_subrequest, or echo_subrequest_async directives.
|
|
Lua tables can be used for both requests and responses when the number of subrequests to be issued is not known in advance:
|
|
Capture
|
|
重定向
|
|
伪异步
|
|
与客户端断开连接,但是继续向下执行以后的代码,此时nginx进程还没有释放,类似php的fastcgi_request_finish.
ngx.say && ngx.print
|
|
set
|
|
header_filter_by_lua:增加response header
|
|
ngx.arg
When this is used in the context of the set_by_lua or set_by_lua_file directives, this table is read-only and holds the input arguments to the config directives:
|
|
Here is an example
12345678
location /foo { set $a 32; set $b 56; set_by_lua $sum 'return tonumber(ngx.arg[1]) + tonumber(ngx.arg[2])' $a $b; echo $sum; }
that writes out 88, the sum of 32 and 56.
HTTP方法常量
|
|
HTTP status常量
|
|
Nginx log level constants
|
|
ngx.ctx:在一个请求中传递变量
This table can be used to store per-request Lua context data and has a life time identical to the current request (as with the Nginx variables).
Consider the following example,
|
|
That is, the ngx.ctx.foo entry persists across the rewrite, access, and content phases of a request.
Every request, including subrequests, has its own copy of the table. For example:
123456789101112131415161718
location /sub { content_by_lua ' ngx.say("sub pre: ", ngx.ctx.blah) ngx.ctx.blah = 32 ngx.say("sub post: ", ngx.ctx.blah) ';}location /main { content_by_lua ' ngx.ctx.blah = 73 ngx.say("main pre: ", ngx.ctx.blah) local res = ngx.location.capture("/sub") ngx.print(res.body) ngx.say("main post: ", ngx.ctx.blah) ';}
Then GET /main will give the output
1234
main pre: 73sub pre: nilsub post: 32main post: 73
Here, modification of the ngx.ctx.blah entry in the subrequest does not affect the one in the parent request. This is because they have two separate versions of ngx.ctx.blah.
Internal redirection will destroy the original request ngx.ctx data (if any) and the new request will have an empty ngx.ctxtable. For instance,
123456789101112
location /new { content_by_lua ' ngx.say(ngx.ctx.foo) ';} location /orig { content_by_lua ' ngx.ctx.foo = "hello" ngx.exec("/new") ';}
Then GET /orig will give
1
nil
ngx.status:设置或获取nginx status
|
|
Setting ngx.status after the response header is sent out has no effect,but leaving an error message in your nginx’s error log file:
attempt to set ngx.status after sending out response headers
ngx.header.HEADER
syntax: ngx.header.HEADER = VALUE
syntax: value = ngx.header.HEADER
header name中的下划线默认会被替换成中划线,lua_transform_underscores_in_response_headers可以关闭。
The header names are matched
|
|
|
|
in the response headers.
Setting a slot to nil effectively removes it from the response headers:
|
|
The same applies to assigning an empty table:
1
ngx.header["X-My-Header"] = {};
This is particularly useful in the context of header_filter_by_lua and header_filter_by_lua_file, for example,
12345678910111213
location /test { set $footer ''; proxy_pass http://some-backend; header_filter_by_lua ' if ngx.header["X-My-Header"] == "blah" then ngx.var.footer = "some value" end '; echo_after_body $footer;}
For multi-value headers, all of the values of header will be collected in order and returned as a Lua table. For example, response headers Foo: bar Foo: baz
will result in
1
{"bar", "baz"}
to be returned when reading ngx.header.Foo.
ngx.resp.get_headers/ngx.req.get_headers:获取header
syntax: headers = ngx.resp.get_headers(max_headers?, raw?)
context: set_by_lua, rewrite_by_lua, access_by_lua, content_by_lua, header_filter_by_lua, body_filter_by_lua, log_by_lua**
Returns a Lua table holding all the current response headers for the current request.
|
|
ngx.req.start_time:返回当前请求被创建的时间
|
|
ngx.req.http_version获取 http 版本
ngx.req.raw_header(bool no_request_line):获取原始header字符串
参数no_request_line决定是否返回 ‘GET /t HTTP/1.1’ 类似的请求信息
ngx.req.get_method()、ngx.req.set_method:获取、设置method
ngx.req.set_uri
syntax: ngx.req.set_uri(uri, jump?)
For instance, Nginx config
|
|
can be coded as
12
ngx.req.set_uri_args("a=3")ngx.req.set_uri("/foo", true)
or
12
ngx.req.set_uri_args({a = 3})ngx.req.set_uri("/foo", true)
ngx.req.set_uri_args
|
|
ngx.req.get_uri_args:获取url参数
|
|
Then GET /test?foo=bar&bar=baz&bar=blah will yield the response body
|
|
Arguments without the = parts are treated as boolean arguments. GET /test?foo&bar will yield:
12
foo: truebar: true
GET /test?foo=&bar= will give something like
12
foo:bar:
Updating query arguments via the nginx variable $args (or ngx.var.args in Lua) at runtime is also supported:
12
ngx.var.args = "a=3&b=42"local args = ngx.req.get_uri_args()
Here the args table will always look like
1
{a = 3, b = 42}
在一个nignx worker内共享数据
|
|
最后:
ffi的使用
参考: phper
我们知道原生lua如果我们想使用sleep方法,只能借助于os这个模块,这种就不再多说。下面采用luajit的ffi模块去实现sleep。下面介绍两种方法,大题上都是一样的通过luajit的ffi模块去调用C的方法。
借助C里的poll方法(如果你不熟悉poll方法,可以通过man 2 去查看帮助文档)
local ffi=require('ffi')
ffi.cdef[[
void Sleep(int ms);
int poll(struct pollfd *fds, unsigned long nfds, int timeout);
]]
local sleep
if ffi.os == "Windows" then
function sleep(s)
ffi.C.Sleep(s*1000)
end
else
function sleep(s)
ffi.C.poll(nil, 0, s*1000)
end
end
for i=1, 2 do
ngx.say(".")
ngx.flush()
sleep(1)
end
借助C的select方法(如果你不熟悉select方法,可以通过man 2 select去查看帮助文档),此方法可以精确到纳秒
local ffi=require('ffi')
ffi.cdef[[
int select(int nfds, struct fd_set *readfds, struct fd_set *writefds, struct fd_set *exceptfds, const struct timespec *timeout);
struct timespec { long tv_sec; long tv_nsec; };
]]
local time = ffi.new("struct timespec", {5, 200000})
ffi.C.select(1,nil,nil,nil,time)
ngx.say("sleep finish")
需要注意的是: ffi.cdef的时候如果定义struct,不要使用typedef的方式,如果使用这种方式,将不能使用ffi.new
参考:
Lua 是一种语法简单,上手快的语言,虽然原生库比较少,但是可以方便的和 C 语言互相调用,常被用于脚本嵌入到 C 程序中。如 Redis 中可以加载 Lua 脚本,作用类似于存储过程,Nginx 中 lua-nginx-module 模块更是将 Lua 的这种特性发挥到极致。
使用 Lua 如何调用 C 的函数,个人认为是每一个 Lua 开发者必学的内容。Lua 调用 C 程序有两种方法,一种是使用 lua C API,另一种方法就是使用 luajit 提供的 ffi 库来调用 C 程序。本文主要是对 luajit ffi 的研究总结。
#luajit ffi
luajit 和 lua 一样,是可以直接安装在操作系统中的,相关介绍直接参考官网 luajit。个人测试效果来看,luajit 的执行效率远高于 lua,大概是 8 倍左右。openresty 的 lua-nginx-module 模块就是将 luajit 集成到了 Nginx 中,实现在 Nginx 中执行 Lua 脚本
luajit ffi 是 luajit 提供给 Luaer 使用 Lua 调用 C 函数的 Lua 库,使用该库,Luaer 不用再去操作复杂的 Lua 栈来粘合两种程序代码,luajit ffi 官方资料。
##引入 luajit ffi 库
local ffi = require("ffi")
#在 Lua 中调用 C 函数
和 lua 的 C API 一样,Lua 调用 C 函数,需要将 C 函数编译成链接库。区别在于 C API 查找 C 的 Lua 库是在 package.cpath 路径下进行查找,而这些库函数使用 Lua 栈接口进行编写。而 luajit 对于 C 链接库的引用遵从于普通 C 库的引用方式,先在 /usr/lib(/usr/lib64),/lib(/lib64) 目录下查找,再到用户自定义的 LD_LIBRARY_PATH 下查找。
本节涉及接口:
ffi.cdef[[c_function define]]
ffi.C
ffi.load(name [,global])
调用 C 标准库函数
对于 C 标准库函数引用,需要引入函数,函数声明
ffi.cdef[[c_function define]]
调用 C 函数
ffi.C.c_function
如:
local ffi = require("ffi")
ffi.cdef[[
int printf(const char *fmt, ...);
int strcasecmp(const char *s1, const char *s2);
]]
ffi.C.printf("Hello %s!\n", "world")
ret = ffi.C.strcasecmp("Hello", "hello")
print(ret)
ret = ffi.C.strcasecmp("Hello", "hello1")
print(ret)
输出结果
[root@AlexWoo-CentOS lua]# luajit ffic.lua
Hello world!
0
-49
调用自定义的 C 函数
调用自定义的 C 函数,首先要将自定义的 C 函数编译成链接库
[root@AlexWoo-CentOS lua]# cat ffimyc.c
int add(int x, int y)
{
return x + y;
}
[root@AlexWoo-CentOS lua]# gcc -g -o libffimyc.so -fpic -shared ffimyc.c
调用 C 标准库函数
调用 C 标准库函数,需要在 Lua 中引入相应的库
ffi.load(name [,global])
这里第二个参数如果为 true,则该库被引入全局命名空间,这里使用 ffi.load 需要注意两点:
链接库文件必须在 C 的动态链接库查找路径中,否则会报类似错误:
luajit: ffimyc.lua:3: libffimyc.so: cannot open shared object file: No such file or directory
引入方法:
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:your_lib_path
在 Linux 下,库函数名的查找与 C 程序查找动态链接库相同,如上面我生成的动态链接库文件为 libffimyc.so,我在 ffi.load 中的 name 为 ffimyc
调用自己的函数,可以直接使用 ffi.load 返回的变量调用,下面我们看一个简单的例子:
local ffi = require('ffi')
myc = ffi.load('ffimyc')
ffi.cdef[[
int add(int x, int y);
]]
ret = myc.add(1, 20)
print(ret)
输出结果
[root@AlexWoo-CentOS lua]# luajit ffimyc.lua
21
使用 ffi.C 调用自定义的 C 函数
上面的例子中,是不能直接使用 ffi.C 来调用 add 函数的,那么怎么用 ffi.C 来调用 add 函数,对,就是 ffi.load 时,第二个参数置为 true,将库加载为全局命名空间。示例:
local ffi = require('ffi')
ffi.load('ffimyc', true)
ffi.cdef[[
int add(int x, int y);
]]
ret = ffi.C.add(1, 10)
print(ret)
输出结果
[root@AlexWoo-CentOS lua]# luajit ffimyc.lua
11
本节小结
在 lua 中调用 C 函数,需要使用 ffi.cdef 对 C 函数进行声明
对于 C 标准库函数,已在全局命名空间,直接可以使用 ffi.C.函数名(函数参数…) 来调用函数
对于自定义的 C 函数,需要将其先编译成链接库,并将链接库所在路径加入到 LD_LIBRARY_PATH 中,需要使用 ffi.load 载入链接库
如果 ffi.load 第二个参数不填写,链接库以私有空间方式链入 Lua 脚本,使用时需要用 ffi.load 的返回值对函数进行调用
如果 ffi.load 第二个参数设置为 true,可以使用 ffi.C 直接调用,调用方法同 C 标准库函数的调用
Lua 处理 cdata 对象
上面对 Lua 如何调用 C 函数进行了小结,但是光能调用 C 函数是远远不够的,我们还需要对 C 的变量,变量类型进行处理。本节将对这部分进行探讨。
C 类型转化为 Lua 中的 ctype
C 类型转化为 Lua ctype,使用 ffi.typeof,该函数返回一个 ctype 变量类型
ctype = ffi.typeof(ct)
示例:
local ffi = require('ffi')
ffi.cdef[[
struct s1 {
int a;
int b;
};
typedef struct {
int c;
int d;
} s2;
union u {
int a;
long b;
float c;
};
enum e {
Male,
Female
};
]]
print(ffi.typeof("int8_t"))
print(ffi.typeof("uint8_t"))
print(ffi.typeof("int16_t"))
print(ffi.typeof("uint16_t"))
print(ffi.typeof("int32_t"))
print(ffi.typeof("uint32_t"))
print(ffi.typeof("int64_t"))
print(ffi.typeof("uint64_t"))
print(ffi.typeof("double"))
print(ffi.typeof("float"))
print(ffi.typeof("bool"))
print(ffi.typeof("struct s1"))
print(ffi.typeof("s2"))
print(ffi.typeof("union u"))
print(ffi.typeof("enum e"))
print(ffi.typeof("struct s1*"))
print(ffi.typeof("struct s1[]"))
输出:
[root@AlexWoo-CentOS lua]# luajit ffit.lua
ctype<char>
ctype<unsigned char>
ctype<short>
ctype<unsigned short>
ctype<int>
ctype<unsigned int>
ctype<int64_t>
ctype<uint64_t>
ctype<double>
ctype<float>
ctype<bool>
ctype<struct s1>
ctype<struct 98>
ctype<union u>
ctype<enum e>
ctype<struct s1 *>
ctype<struct s1 []>
创建并初始化 cdata 对象
使用 ctype 有以下两种构造 Lua C 对象的方法
cdata = ffi.new(ct [,nelem] [,init...])
cdata = ctype([nelem,] [init...])
基本类型 cdata 对象
首先是一个 C 的函数,我们使用构造的 cadata 对象来调用该函数:
int add(int x, int y)
{
return x+y;
}
直接调用
local ffi = require('ffi')
local t = ffi.load("t", true)
ffi.cdef[[
int add(int x, int y);
]]
print(t.add(10, 11))
执行结果
[root@AlexWoo-CentOS lua]# luajit ffit.lua
21
这种方法仅限于基本类型,lua 会将其基本类型转换为 cdata 的基本类型
使用 ffi.new 构造
local ffi = require('ffi')
local t = ffi.load("t", true)
ffi.cdef[[
int add(int x, int y);
]]
ti = ffi.typeof("int")
a = ffi.new(ti, 10)
b = ffi.new("int", 11)
print(type(a), type(b))
print(t.add(a, b))
执行结果
[root@AlexWoo-CentOS lua]# luajit ffit.lua
cdata cdata
21
这里如果执行 print(ffi.typeof(“int”)),结果就是 ctype,因此这里 ffi.new 的第一个参数直接填为 “int” 与传入一个 ctype 的类型对象是等价的
使用类型对象构造
local ffi = require('ffi')
local t = ffi.load("t", true)
ffi.cdef[[
int add(int x, int y);
]]
ti = ffi.typeof("int")
a = ti(10)
b = ti(11)
print(t.add(a, b))
执行结果
[root@AlexWoo-CentOS lua]# luajit ffit.lua
21
基本类型指针 cdata 对象
首先是一个 C 的函数,我们使用构造的 cadata 对象来调用该函数:
int addp(int *x, int *y)
{
return *x+*y;
}
这里构造指针对象可以使用 ffi.new 和 类型构造两种方法,下面只以一种进行举例,其它举一反三
local ffi = require('ffi')
local t = ffi.load("t", true)
ffi.cdef[[
int add(int x, int y);
int addp(int *x, int *y);
]]
a = ffi.new("int[1]", {10})
b = ffi.new("int[1]", {10})
print(t.addp(a, b))
执行结果
[root@AlexWoo-CentOS lua]# luajit ffit.lua
21
没有将 Lua 原生类型直接转换为指针类型的方法(至少我没找到),这里使用的是将 Lua 的 table 转为只有一个元素的数组,并将数组当作指针类型参数传入addp中。
结构类型 cdata 对象
首先是一个 C 程序,我们使用构造的 cadata 对象来调用该函数:
#include <stdio.h>
struct constr_t {
int a;
int b;
struct innerstr {
int x;
int y;
} c;
};
void print_constr_t(struct constr_t t)
{
printf("a:%d\n", t.a);
printf("b:%d\n", t.b);
printf("c.x:%d\n", t.c.x);
printf("c.y:%d\n", t.c.y);
}
Lua 程序
local ffi = require('ffi')
local t = ffi.load("t", true)
ffi.cdef[[
struct constr_t {
int a;
int b;
struct innerstr {
int x;
int y;
} c;
};
void print_constr_t(struct constr_t t);
]]
a = ffi.new("struct constr_t", {1, 2, {10, 11}})
t.print_constr_t(a)
执行结果
[root@AlexWoo-CentOS lua]# luajit ffit.lua
a:1
b:2
c.x:10
c.y:11
这里我们看到构造一个 C 的结构类型与基本类型的方法基本类似,唯一区别就是需要使用 table 来进行构造,table 的层次结构与 C 的结构的层次必须符合
结构类型指针 cdata 对象
在日常使用中,对于结构体,我们更常使用的是指针。和基本类型指针 cdata 对象不同,可以直接使用与结构类型 cdata 对象相同的方式来构造结构类型指针的 cdata 对象
C 程序
#include <stdio.h>
struct constr_t {
int a;
int b;
struct innerstr {
int x;
int y;
} c;
};
void print_pconstr_t(struct constr_t *t)
{
printf("a:%d\n", t->a);
printf("b:%d\n", t->b);
printf("c.x:%d\n", t->c.x);
printf("c.y:%d\n", t->c.y);
}
Lua 程序
local ffi = require('ffi')
local t = ffi.load("t", true)
ffi.cdef[[
struct constr_t {
int a;
int b;
struct innerstr {
int x;
int y;
} c;
};
void print_pconstr_t(struct constr_t *t);
]]
a = ffi.new("struct constr_t", {1, 2, {10, 11}})
t.print_pconstr_t(a)
执行结果
[root@AlexWoo-CentOS lua]# luajit ffit.lua
a:1
b:2
c.x:10
c.y:11
字符串 cdata 对象
可以使用 Lua string 对象来初始化字符串 cdata 对象
C 程序
void print(const char *s)
{
printf("%s\n", s);
}
Lua 程序
local ffi = require('ffi')
local t = ffi.load("t", true)
ffi.cdef[[
void print(const char *s);
]]
a = ffi.new("const char*", "Hello World")
t.print(a)
执行结果
[root@AlexWoo-CentOS lua]# luajit ffit.lua
Hello World
注意对字符串,ffi.new 第一个参数只能是 const char 、const char[size] 或 char[size],不能是 char ,const char[?] 等类型
使用 cdata 对象
本节将探讨在 Lua 中怎么使用 cdata 对象
C 程序
#include <stdio.h>
struct constr_t {
int a;
int b;
struct innerstr {
int x;
int y;
} c;
};
void print_pconstr_t(struct constr_t *t)
{
printf("a:%d\n", t->a);
printf("b:%d\n", t->b);
printf("c.x:%d\n", t->c.x);
printf("c.y:%d\n", t->c.y);
}
int print_i(int x)
{
printf("x: %d\n", x);
}
int print_pi(int *px)
{
printf("px: %d\n", *px);
}
void print(const char *s)
{
printf("%s\n", s);
}
Lua 程序
local ffi = require('ffi')
local t = ffi.load("t", true)
ffi.cdef[[
struct constr_t {
int a;
int b;
struct innerstr {
int x;
int y;
} c;
};
void print_pconstr_t(struct constr_t *t);
int print_i(int x);
int print_pi(int *px);
void print(const char *s);
]]
ti = ffi.new("int", 10)
tpi = ffi.new("int[1]", {20})
ts = ffi.new("struct constr_t", {1, 2, {3, 4}})
tcstr = ffi.new("const char*", "Hello World")
tstr = ffi.new("char[11]", "Hello World")
t.print_i(ti)
--t.print_pi(ti) --luajit: ffit.lua:29: bad argument #1 to 'print_pi' (cannot convert 'int' to 'int *')
--t.print_i(tpi) --luajit: ffit.lua:31: bad argument #1 to 'print_i' (cannot convert 'int [1]' to 'int')
t.print_pi(tpi)
t.print_pconstr_t(ts)
t.print(tcstr)
t.print(tstr)
–对基本类型操作
ti = 100 --change tpi to number
tpi[0] = 21
--tpi=22 --change tpi to number
--tpi[1] = 2000 --luajit: ffit.lua:44: attempt to index global 'tpi' (a number value)
print(type(ti), type(tpi))
t.print_i(ti)
t.print_pi(tpi)
–对 struct 类型操作
ts.b = 100
ts.c.y = 1000
print(type(ts))
t.print_pconstr_t(ts)
–对字符串类型操作
--tcstr[2] = 32 --luajit: ffit.lua:54: attempt to write to constant location
tstr[2] = 32
t.print(tstr)
t.print("Hello Lua")
执行结果
[root@AlexWoo-CentOS lua]# luajit ffit.lua
x: 10
px: 20
a:1
b:2
c.x:3
c.y:4
Hello World
Hello World
number cdata
x: 100
px: 21
cdata
a:1
b:100
c.x:3
c.y:1000
Hello World
Hello Lua
从上面的例子可以看出,对基本类型,实际上不需要将其转为 cdata 类型;对于基本类型指针,操作方式与数组类似,在 Lua 中可当作 table 数组进行处理;对结构类型,在 Lua 中可当作 table 字典进行处理;对字符串,在 Lua 中可当作 table 数组进行处理
本节小结
Lua 可以使用 ffi.new 初始化一个 cdata 对象,也可以使用 ffi.typeof 生成的类型来初始化一个 cdata 对象
对于基本类型和字符串类型,没有必要将其转为 cdata 对象,其可以作为参数传入 C 函数中。也可以接收 C 函数的返回值
对于基本类型指针对象,可以使用单元素数组进行初始化,可以使用数组元素赋值的方式改变其中的值
对于结构类型,可以传入 C 指针参数,也可以传入 C 普通参数。对结构类型的操作,与 table 的字典操作类似
原文出自: http://blog.csdn.net/alexwoo0501/article/details/50636785
Bryan Huges在twitter中写道:如果你没有在你的node服务前加一层nginx,那么你这么做可能是不正确的。
Node.js在用世界最著名的语言javascript去创建服务端应用的工具中处于领先地位。它同时提供了一个web服务器又和一个应用服务器的的功能。现在Node.js被当做开发和交付各类微服务的一个关键工具。
Node.js可以替代或增强Java或.NET用作后端应用程序的开发。
Node.js使用了单线程非阻塞IO,使其能够扩展并支持数万并发操作。Nginx也是使用这种架构去解决C10K(支持多于10000个并发连接)问题。Node.js以其高性能和开发人员的生产力而著称。
那哪里错了呢?
Node.js也有一些薄弱的环节和缺点,导致基于Node的系统容易表现的性能不好甚至崩溃。当问题频繁出现时,会引起基于Node的web应用程序流量大增。
此外,Node.js是一个强大的工具能用来创建和运行应用逻辑,为你的网页产生核心的变量。但是它不那么擅长服务静态内容(比如图片,javascript文件)、在多个服务器之间进行负载均衡。
为了最大化发挥Node.js的作用,你需要缓存静态内容,在多个应用服务器之间进行代理,进行负载均衡。还需要管理客户端、Node.js以及其他服务(比如一个运行Socket.IO的服务)之间的端口争用。Nginx可以被用来做这些,使之成为Node.js性能优化的一个很棒的工具。
使用这些tips提高Node.js应用的性能
注: 一种快速解决Node.js应用程序的性能的办法是修改你的Node.js的配置,以充分利用现代多核服务器的优势。看看这篇文章,以了解如何将Node.js的派生单独的子进程(在你的web服务器上子进程等于CPU的数量),每个进程都能充分利用一个CPU,给你的应用一个很大的性能提升
##1. 部署一个反向代理服务器
当我们看到应用服务器直接暴露在互联网上被当作高性能网站的核心传入流量,我们(Nginx Inc.)总是有点恐惧。比如包括许多基于WordPress的,还有Node.js的网站。
Node.js的扩展性在更大程度上比大多数应用服务器设计的更好,它的web服务器可以很好的处理大量的互联网流量。但是web服务不是Node.js构建的适合做的。
如果你有一个高流量的站点,提高应用性能的第一步是在你的Node.js服务前放一台代理服务器,这样可以防止你的Node.js服务直接暴露在互联网的流量中,并且在你使用多台应用服务器进行负载均衡时有很高的灵活性在,并且可以用内部链接去缓存内容。
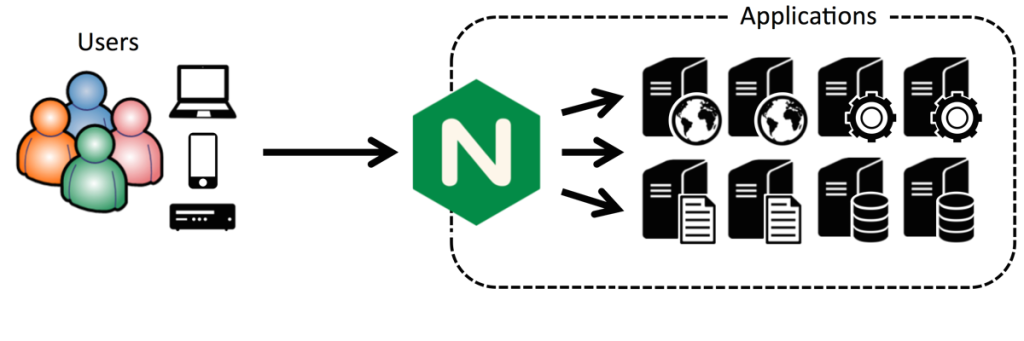
在现有的服务器前方搭建一台Nginx作为反向代理服务器,是nginx的一个核心用例,世界上已经有数以千万计的站点都这么用了。
这有一篇特别的高级的文章使用Nginx作为一个Node.js的反向代理服务器 包括:
注 : 这些教程讲解如何使用NGINX作为在Ubuntu14.04或CentOS的环境反向代理服务器,而且对那些想把NGINX放到node.js前的人来说是很有用的概述。
##2. 缓存静态文件
随着一个基于Node.js的站点的成长,服务器开始显示的疲惫。这有亮点你希望做的:
这实际上做起来很简单,就像上面第一个tips里面说的那样,部署一个Nginx作为反向代理,很简单就实现了缓存,负载均衡(当你有多台Node.js服务器的时候)等功能。
一个应用容器平台Modulus(用作系数压测)的网站有一篇文章压力测试nginx和Node.js应用的性能,作者的网站能够为平均每秒服务近900请求。使用NGINX作为反向代理服务器,提供静态内容,同一站点提供超过每秒1600请求 - 近2倍的性能提升。
如果再性能加倍你就要花费时间去采取额外的措施,以适应近一步的增长,比如审查(或者改进)一下你站点的设计,优化一下你的应用代码或者部署更多的应用服务器。
以下是配置代码,适用于Modulus上运行的网站:
server {
listen 80;
server_name static-test-47242.onmodulus.net;
root /mnt/app;
index index.html index.htm;
location /static/ {
try_files $uri $uri/ =404;
}
location /api/ {
proxy_pass http://node-test-45750.onmodulus.net;
}
}
这篇详细的文章来自于NGINX公司的Patrick Nommensen,解释了他如何缓存他运行的Ghost开源博客平台Node.js应用程序的静态内容。虽然有些细节是Ghost特有的,你可以复用一些代码到很多其他的Node.js应用程序。
例如,在Nginx的location块中,你可能会想不缓存某些内容。你通常不会想要缓存博客平台的管理界面,例如。下面是禁用[或不缓存]Ghost管理界面的缓存配置代码:
location ~ ^/(?:ghost|signout) {
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header Host $http_host;
proxy_pass http://ghost_upstream;
add_header Cache-Control "no-cache, private, no-store,
must-revalidate, max-stale=0, post-check=0, pre-check=0";
}
有关提供静态内容的一般信息,请参阅NGINX Plus管理指南。管理员指南包括实现更快的性能配置说明,尝试查找文件时相应成功或失败的多种选项,达到更快的性能的优化方法。
缓存静态文件的NGINX服务器显著从Node.js的应用程序服务器卸载一部分工作,使其达到更高的性能。
https://www.nginx.com/blog/5-performance-tips-for-node-js-applications/
说起nginx自定义access.log,可能大家都不陌生,有的同学会说,那不就是定义一下format, format里面可以使用nginx内置的变量$remote_addr、$status、$http_user_agent、$time_local etc… (更多nginx内置的变量) , 这种咱们就不说了,这个简单,基本大家都会。
那是自定义access.log的名字? 比如在一个多个虚拟主机的nginx中,我们想根据不同的server去生成不同的access.log。这样我们去查access.log的时候也方便,从名字一眼就能看出要去哪个文件去查。你也可以通过上面nginx内置的变量去给文件命名,比如我用server_name去命名,我就可以这样写:
log_format log/$http_host.access.log
然后reload一下nginx就可以了。当然我要说的也不是这个。
其实我想说的是这种:自定义log_format 在log_format里面添加一些自己自定义的变量(openresty群里一个朋友问到这个问题)。
比如我想给每个HTTP请求的access.log中添加一个UUID字符串。你可能要问这东西有什么用呢?你想一下,对于一些POST请求(也可能是GET请求),你从URL上看不出差别,但是因为POST的body太大,你又不想记到nginx的access.log里面,还有一种可能是你POST的body里面是二进制,即便你记录到access.log里面了,等你遇到问题要去查的时候你就发现”然并卵啊”,记录这东西也没啥用(是不是想哭),不用哭,今天就是介绍这个的。
我们可以通过一个唯一的字符串去标记一个请求,然后这个串可以通过HTTP的Header或者通过QueryString传给我们的A\B\C\D…服务器,直到一个请求周期结束。然后我们在需要记录log的地方可以将这个unique的串也记录下来,如果你把日志都集中存储到了一个地方(比如ELK),当你去查问题的时候,你可以通过这个字符串就搜索到了这个请求的整个生命周期,是不是有点爽呢。 不扯淡了,下面就说说怎么搞的,这里用了nginx和lua去做,至于为啥用lua,说因为任性可以不,其实就是为了玩。
如果没听过lua或者nginx,再如果不敢兴趣,那只能说不好意思,这位客官,你可能只能观一下了。想了解的同学可以自行搜索一下这俩玩意。如果已经了解了这俩东西不了解ngx_lua(或者openresty)的也可以去搜索一下,这俩项目都是@agentzh (章亦春)春哥的大作。这里我为了简单,就选用了ngx_lua。
先说下lua生产随机数字吧,我把代码放到util.lua里面了
local os = require('os')
local math = require('math')
local io = require("io")
local _M = {}
_M.uuid = function()
local template = "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
d = io.open("/dev/urandom", "r"):read(4)
math.randomseed(os.time() + d:byte(1) + (d:byte(2) * 256) + (d:byte(3) * 65536) + (d:byte(4) * 4294967296))
return string.gsub( template, "x",function (c)
local v = (c == "x") and math.random(0, 0xf) or math.random(8, 0xb)
return string.format("%x", v)
end)
end
return _M
这里采用了从/dev/urandom去读取随机数,读了前4位,然后根据时间、前四位字符的ascii分作为随机数的种子,然后去随机参数字符替换template里面的x,你也可以再加其他去作为随机数发射器的种子比如pid,不过在lua中,你可能还需要posix这个module,最终生成一个32位的字符串。
那就直接亮出nginx的配置吧
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for" "$uuid"';
access_log logs/access.log main buff=4k;
sendfile on;
tcp_nopush on;
#keepalive_timeout 0;
keepalive_timeout 65;
lua_package_path "$prefix/lua/?.lua;/test/lua/?.lua;";
init_by_lua_file lua/util.lua;
注意看,其他字段都没改,懒得连main都没改,只是最后添加了一个自定义的字段叫’”$uuid”‘, 还有你的\lua_package_path以及init_by_lua_file位置一定要写正确,不然会因为找不到文件报错。然后看下相关server里面的配置。
server {
listen 80 backlog=512;
server_name localhost;
charset utf-8;
underscores_in_headers on;
set_by_lua_block $uuid {
local util = require('util')
local uniq_id, _ = util.uuid()
return uniq_id
}
location /redirect {
return 301 http://127.1/lua;
}
location /lua {
default_type "text/plain";
content_by_lua_block {
local args = ngx.req.get_uri_args()
for key, val in pairs(args) do
if type(val) == "table" then
ngx.say(key, ": ", table.concat(val, ", "))
else
ngx.say(key, ": ", val)
end
end
ngx.say(ngx.var.arg_b)
}
}
...
只贴这么多关键部分吧,然后去check一下配置是否有问题
[sky@10_211_55_6_VM_CENTOS go]> sudo /opt/soft/nginx/sbin/nginx -t
nginx: [alert] lua\_code\_cache is off; this will hurt performance in /opt/soft/ nginx1.9.3/conf/nginx.conf:35
nginx: the configuration file /opt/soft/nginx1.9.3/conf/nginx.conf syntax is ok
nginx: configuration file /opt/soft/nginx1.9.3/conf/nginx.conf test is successful
这个警告是因为开发阶段lua_code_cache没开,生产环境是一定要开的,为了我们修改lua代码能及时生效。那我们去试试看下效果先
[sky@10_211_55_6_VM_CENTOS go]> curl -iL 'http://127.1/redirect?a=1&b=2&c=3'
HTTP/1.1 301 Moved Permanently
Server: nginx/1.9.3
Date: Thu, 05 Nov 2015 16:34:03 GMT
Content-Type: text/html
Content-Length: 184
Connection: keep-alive
Location: http://127.1/lua
然后去看下access.log的内容
[sky@10_211_55_6_VM_CENTOS go]> tail -n 2 /opt/soft/nginx/logs/access.log
127.0.0.1 - - [05/Nov/2015:13:32:09 +0800] "GET /lua HTTP/1.1" 200 14 "-" "curl/7.19.7 (x86_64-redhat-linux-gnu) libcurl/7.19.7 NSS/3.19.1 Basic ECC zlib/1.2.3 libidn/1.18 libssh2/1.4.2" "-" "8272ba28283350d51056995be1f0c244"
127.0.0.1 - - [05/Nov/2015:23:56:55 +0800] "GET /lua HTTP/1.1" 200 14 "-" "curl/7.19.7 (x86_64-redhat-linux-gnu) libcurl/7.19.7 NSS/3.19.1 Basic ECC zlib/1.2.3 libidn/1.18 libssh2/1.4.2" "-" "118ab63e5bf8e8c0a2d04e7ab898120d"
透传给应用层
如果你通过fastcgi协议传递给后端的PHP,你可以使用fastcgi_param
proxy_set_header HTTP_UUID $uuid;
…
fastcgi_param HTTP_UUID $uuid;
注意:nginx对对header name的字符做了限制,默认 underscores_in_headers 为off,表示如果header name中包含下划线,则忽略掉。
解决办法: